The Problem
GCC law firms operate across two distinct legal traditions — civil law systems influenced by Egyptian and French codes, and sharia-based family and commercial law. A senior associate at a mid-sized Kuwaiti firm could spend three to four hours per case simply locating and cross-referencing relevant precedents and statutory provisions across Arabic and English source materials.
Existing legal research tools were built for US or UK law. They had no understanding of GCC legal structures, no Arabic language support worth using, and pricing models designed for large Western firms that made them inaccessible to regional practices.
What We Built
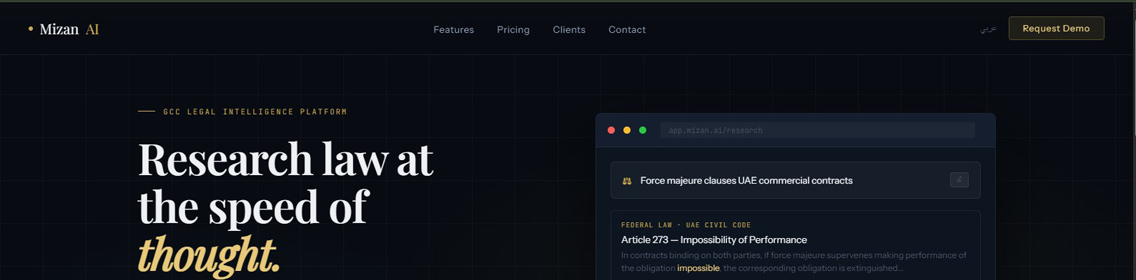
Mizan AI is a multi-tenant SaaS platform that lets GCC law firms upload their document libraries and search across them using natural language — in Arabic or English. The underlying architecture uses retrieval-augmented generation (RAG): queries are converted to embeddings, matched against a pgvector index of the firm's document corpus, and the retrieved passages are used as context for a language model that generates a cited answer.
The platform is built on a row-level multi-tenant architecture — each firm's data is completely isolated, search indexes are maintained per-tenant, and billing is handled through Stripe subscription plans with per-seat pricing.
Core Features
Natural language queries matched against document embeddings. Finds conceptually related content, not just keyword matches — critical for legal language where the same concept has multiple formulations.
Full Arabic RTL and English interfaces. Users switch language per session. AI responses are generated in the language the query was asked in — Arabic query, Arabic answer with Arabic citations.
Three permission levels: Partner (full access + billing), Associate (search + upload), Paralegal (search only). Audit logs on all document access for compliance.
PDF, Word, and scanned document support. OCR via Tesseract for scanned Arabic documents. Chunking and embedding handled asynchronously via Laravel queues.
Stripe-powered plans with per-seat pricing, trial periods, and usage-based overages for document storage. Arabic invoice generation included.
Every AI-generated answer includes source citations linked back to the original document and page. No hallucinated references — answers are grounded in the firm's actual documents.
Technical Architecture
The application runs on Laravel 11 with a PostgreSQL database extended with pgvector for similarity search. Each document chunk is embedded using OpenAI's text-embedding-3-large model and stored as a 1,536-dimension vector. At query time, the user's question is embedded using the same model and the top-k nearest chunks are retrieved via cosine similarity.
We chose row-level multi-tenancy over separate databases after evaluating the client's projected growth. Row-level isolation gives per-tenant data separation at lower infrastructure cost, with the trade-off that a misconfigured query scope could leak data across tenants. We addressed this with a global Laravel model scope that applies the tenant filter at the Eloquent level and a suite of integration tests that verify isolation on every deployment.
The document processing pipeline uses Laravel Horizon for queue monitoring. Large document batches are chunked into 512-token segments with a 64-token overlap to preserve context across chunk boundaries — a standard RAG pattern that meaningfully improves retrieval quality for long legal documents.
The Result
Associates at the initial pilot firms reported reducing research time from three to four hours down to 45–90 minutes per case. The platform reached 500 active users across 15 firms within six months of launch without any paid acquisition — growth driven entirely by referrals between firms in the GCC legal community.
The client is now developing a public document library of GCC statutory materials to expand the platform beyond firm-uploaded documents, which we are supporting as a continued engineering partner.